In the original draft of this post, I compared two data sets of students taking the ALIRA. However, I’m not really comfortable publishing that. I really don’t need anyone trying to play the victim when it’s been me going on a decade now defending my teaching practices and the kind of Latin that I read (and write) with students. It’s too bad, too, because the data are quite compelling. Some day, I’ll share the charts. Until then, you’ll have to take my word on it. You probably already know that I don’t fuck around, either, so my word is solid.
In short, the charts will contradict the claim that reading non-Classical Latin leaves students unprepared for reading Classical Latin. They will suggest that reading non-Classical Latin texts, such as those rife with Cognates & Latinglish via class texts and novellas, is of no disadvantage. They will also suggest that reading Classical texts is of no advantage. That’s all I’m prepared to share, for now.
Once a lot more data like these will be presented, though, the jury will start to come in on the matter of what kind of Latin prepares students for any other Latin. From what I’ve seen so far, it looks like A LOT of any Latin can prepare students to read other Latin, and that’s a good thing. These emerging data show that concerns and claims over certain kinds of Latin don’t play out in reality. Still, it’d be good to have more scores, not just the 532 ones currently submitted to that ALIRA form. If this all seems mysterious, it kind of has been. I haven’t shared the spreadsheet yet for viewing. That changes today!
In getting the spreadsheet ready with a bunch of summary charts that auto-update as more scores roll in, I’ve also clarified the pedagogical distinction made on the form. Instead of the broad “grammar-focus” or “comprehension-focus” in the original version, I’ve added “Analysis” and text-level to the labels and descriptions. The reason? It’s quite possible that a teacher might have moved away from traditional explicit grammar instruction, but if they’re still using ancient texts far above students’ reading level that should be noted as a factor in how well students read on the ALIRA. The clarifications also might help teachers determine how far towards one approach they might be, because there certainly is a range. For example…
- If you teach out of Wheelock’s, test accuracy of verb synopses sheets, and translate all of Caesar in the second year, that’s a hard 1 (i.e., grammar, error-correction, above-level texts).
- If you follow Cambridge, test for both meaning and accurate forms, and keep all of its passages as-is despite getting evidence that they start to get above your students’ reading level at a certain point, that might be a 3.
- If you don’t have a textbook (i.e., are unbound by a grammatical syllabus), check for understanding during class, read texts like novellas below- and at-level, and prioritize input and comprehension, that’s a hard 6. N.B. notice how speaking Latin is not a prerequisite for this complete focus on comprehension! That’s a biiiiiiig misunderstanding Latin teachers have about CI.
- If a handful of your resources follow a grammatical sequence, you give short quizzes to check understanding (not verb forms), have a reason (i.e., communicative purpose) for activities, and split class time translating slightly above-level texts as well as reading at- or below-level ones, that might be a 4 or 3, depending how much the grammar and above-level texts pull you in that direction.
- 2s and 5s could represent not fully committing to one approach or the other, implementing some practice that pulls you a tad in the other direction.
- etc.
N.B. There’s no middle number representing something like “both approaches, equally” on this form. Why? People tend to choose a neutral option when presented with one because humans typically go for the path of least resistance (i.e., not as much work). Having to identify which focus you lean towards can be a little more work, sure, but gets more accurate results. The alternative would be something like 50-75% of teachers saying they “do a bit of both” and then we wouldn’t have helpful data about either approach.
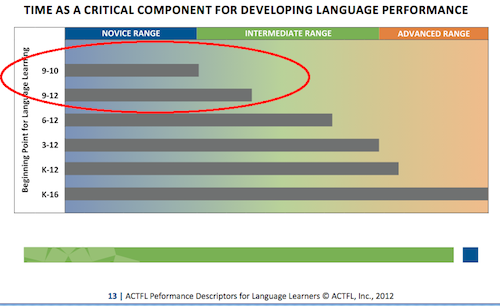
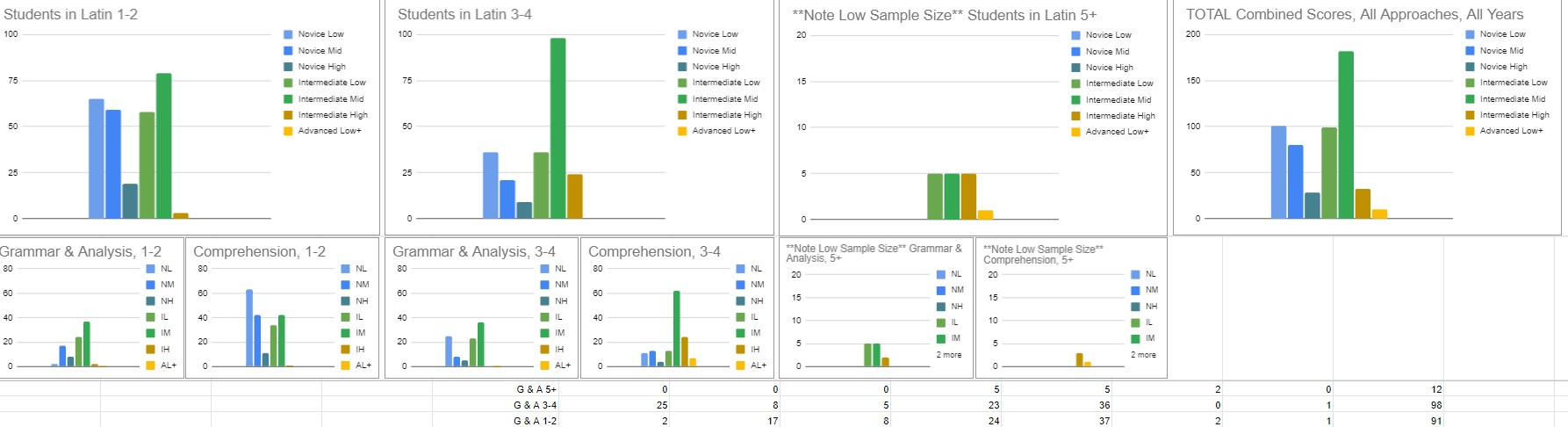
So, I’m asking that you contribute to this unofficial record of national results so that teachers can compare their program to a) other similarly-structured Latin programs, as well as b) differently-structured ones. For example, the national trend—right now—is that just as many students in the first two years of Latin are concentrated at Novice Low/Mid as they are Intermediate Mid/High. Oddly enough, there’s a general lack of Novice High, regardless of experience or teaching approach! Of course, that could just be because teachers whose students do score Novice High haven’t filled out the form…yet. Another trend is that the majority of Latin 3-4 students score Intermediate Mid. Within that, however, there’s also a trend that Grammar & Analysis programs produce students who don’t seem to improve with more experience. They get to Intermediate Mid after the second year, but hang out for another two years. Comprehension-based programs, on the other hand, appear to produce students who improve quite a bit with experience, with scores from these Comprehension-based programs representing the majority of those who reach Intermediate High and Advanced Low. Beyond these pedagogical comparisons, all Latin programs could compare their ALIRA results to ACTFL’s expectations for language learners, too, to see if the majority of their students are out of Novice range sometime in years 3-4, for example.
Or, you can skip this kind of reflection and program eval and just help out everyone else who wants to do it by providing your scores! It should take minutes. You probably have years worth of ALIRA data, too. If I had gift cards to send for your participation, I’d do it, but I’ve also read Alfie Kohn’s Punished By Rewards and really don’t think that kind of bribe is necessary for the good of the profession, right? Without further ado, here’s the link to the live viewable sheet, which will update once more scores get submitted.
N.B. The ALIRA is a single performance score. To put this in an assessment (& grading) context, giving the ALIRA once and making a determination of a student’s performance level is like giving a single quiz, or a single test, or a single paper, or a single exit ticket, or a single observation, and then making an absolute evaluation for the whole course: “65(D),” or “95(A).” The ALIRA is just one datum, which is enough reason to give it more than once. How about each year? There are plenty of district tests that are given multiple times a year. Your school should cough up the dough for ALIRA, no problem.
I can say with confidence that when I gave the ALIRA, only 2-3 students in each class scored in a surprising way (high or low). With my enrollment numbers, that places its reliability at 85%. That’s pretty good, meaning almost all scores align with what I personally see from students in class, performing as well as I’d expect. As for errant high scores, a perfect string of guessing—though quite rare—can skew results on ANY adaptive multiple-choice test, especially one as short as the ALIRA. The test measures how long students sustain understanding at a particular level. Therefore, a ton of lucky guesses in a row means the computer thinks you’re at a higher level than you might be. This probably happened to just one student of mine.
The low scores work differently, though.
In some cases, students are given passages with unfamiliar vocab, which means they can’t understand THAT Latin (even if they can understand a lot of OTHER Latin in class). A series of these can result in that Below Reading (BR) rating. Another, more damning situation, though, is when students overthink and let their monitor influence language processing. At least me and a few other colleagues have suspected that kids with typical common sense get what’s going on in the Latin, while students with a greater understanding of how languages work (i.e., those who have been taught explicit grammar) activate that part of their mind and get thrown off! That’s quite the claim, although there’s support in the literature for explicit knowledge messing with language processing (e.g., Morgan-Short et al. 2012). For now, we should remain vigilant, keep collecting data, and keep reflecting. Who are the students with all the seemingly “off” scores? Either way, one of these scenarios happened to probably six of my students.
Above all, I’m more concerned about the students who sat there and let the timer run down, not really reading or trying to make meaning. I’m more concerned about the students who rapidly clicked through all the choices seemingly without a care in the world (this test is $10 per student—rude!). That’s data, too. This disengagement is important to recognize. It tells its own story. From what I’ve seen, this is perhaps THE story of my 2022-23 9th grade students. No doubt, their formative 7th grade year learning remotely is a factor, but COVID effects are yet to be seen. My prediction? There won’t be much conclusive evidence for years to come until we’ve seen current 3rd graders graduate high school, then COVID will become a case study in what can happen at critical moments of development when the world faces calamity.
